Find Web Resources
Web Resources
Check out this collection of best web resources for advanced media writing and learn how to evaluate a website.
How to Evaluate Sources
Evaluating Sources
While collecting and reviewing sources, how is it determined what is okay to use in academic papers?
Here are 4 considerations when assessing whether or not a source is right for use in assignments.
- Author:
- Who wrote it and what are their credentials? What larger organization are they affiliated with? If an author is search in Google, what is found? Is this article in their area of expertise? Can the author or organization be contacted?
- Bias:
- Can the angle/slant/bias in the article or on an affiliated web site be identified? What is the purpose of the study or content—to prove something to a particular group? Can the claims be corroborated with at least two other sources?
- Content:
- Is the source accurate? Are there basic mistakes in grammar, dead links, or spelling? When was it published, posted, or last updated? Does it contain claims that contradict things known to be true or even other claims within the article itself?
- Support:
- Does the content have citations or sources? Can the source(s) be verified? Do the sources' arguments support the claims of the topic being researched?
Searching Google
oTHER wEB rESOURCES & tOOLS
How To Refine Google Searches
Read Google's Tips on how to refine searches in their search engine.
Remember!: The first result on Google is NOT always the correct answer or best result. ALWAYS verify the result by using the evaluation Guidelines below.
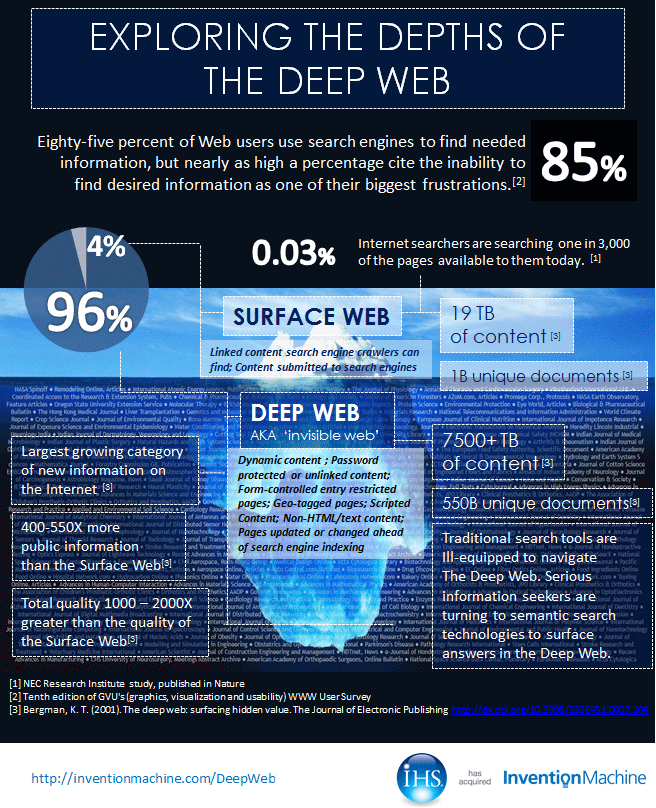
Deep Web
Deep Web
When we search the Web (commonly through Google) most of what we see is on the surface. That's why it is called "the Surface Web." The tools we use are not able to navigate the Deep Web. Also known as "the Invisible Web," the Deep Web includes:
- Dynamic content sources
- Unlinked content pages
- Password-protected websites
- Limited access content pages
- Non-HTML/text content that is text that may be encoded in multimedia files or formats not accessible by search engines.
Data on the Web
Data on the Web 2


http://mobirank.pl/2015/01/10/internet-w-2015-roku/
Understanding Byte Sizes
Click through a category to learn how that amount of data translates.
- 0.1 bytes: A binary decision
- 1 byte: A single character
- 10 bytes: A single word
- 100 bytes: A telegram OR A punched card
- 1 Kilobyte: A very short story
- 2 Kilobytes: A Typewritten page
- 10 Kilobytes: An encyclopaedic page OR A deck of punched cards
- 50 Kilobytes: A compressed document image page
- 100 Kilobytes: A low-resolution photograph
- 200 Kilobytes: A box of punched cards
- 500 Kilobytes: A very heavy box of punched cards
- 1 Megabyte: A small novel OR A 3.5 inch floppy disk
- 2 Megabytes: A high resolution photograph
- 5 Megabytes: The complete works of Shakespeare OR 30 seconds of TV-quality video
- 10 Megabytes: A minute of high-fidelity sound OR A digital chest X-ray
- 20 Megabytes: A box of floppy disks
- 50 Megabytes: A digital mammogram
- 100 Megabytes: 1 meter of shelved books OR A two-volume encyclopaedic book
- 200 Megabytes: A reel of 9-track tape OR An IBM 3480 cartridge tape
- 500 Megabytes: A CD-ROM OR The hard disk of a PC
- 1 Gigabyte: A pickup truck filled with paper OR A symphony in high-fidelity sound OR A movie at TV quality
- 2 Gigabytes: 20 meters of shelved books OR A stack of 9-track tapes
- 5 Gigabytes: An 8mm Exabyte tape
- 10 Gigabytes:
- 20 Gigabytes: A good collection of the works of Beethoven OR 5 Exabyte tapes OR A VHS tape used for digital data
- 50 Gigabytes: A floor of books OR Hundreds of 9-track tapes
- 100 Gigabytes: A floor of academic journals OR A large ID-1 digital tape
- 200 Gigabytes: 50 Exabyte tapes
- 1 Terabyte: An automated tape robot OR All the X-ray films in a large technological hospital OR 50000 trees made into paper and printed OR Daily rate of EOS data (1998)
- 2 Terabytes: An academic research library OR A cabinet full of Exabyte tapes
- 10 Terabytes: The printed collection of the US Library of Congress
- 50 Terabytes: The contents of a large Mass Storage System
- 1 Petabyte: 5 years of EOS data (at 46 mbps)
- 2 Petabytes: All US academic research libraries
- 20 Petabytes: Production of hard-disk drives in 1995
- 200 Petabytes: All printed material OR Production of digital magnetic tape in 1995
- 5 Exabytes: All words ever spoken by human beings.
- If each Terabyte in a Zettabyte were a kilometer, it would be equivalent to 1,300 round trips to the moon and back (768,800 kilometers).
- If each Petabyte in a Zettabyte were a centimeter, then we could reach a height 12 times higher than the Burj Khalifa (the world’s tallest building at 828 meters high).
- If every Gigabyte in a Zettabyte were a meter, it could span the distance of the Amazon River (the world’s longest river at 6,992 kilometers) more than 150,000 times.
- If each Gigabyte in a Zettabyte were a brick, 258 Great Walls of China (made of 3,873,000,000 bricks) could be built.
-
Is NOT named after the Star Wars character Yoda. This commonly cited "fact" appears to have originated from someone making a joke in an article that has since been referenced several times.
-
Its name comes from the prefix ‘Yotta’ derived from the Ancient Greek οκτώ (októ), meaning “eight”, because it is equal to 1,0008
Data taken from Globally Interconnected Object Databases by Julian Bunn, and The Zettabyte Era Officially Begins (How Much is That?) by Thomas Barnett Jr.
Deep Websites
Deep Websites
Deep Websites 2
What is the “deep web”? Briefly, it is the information that is not found by using general search engines, (i.e. Google). The “deep web” generally consists of alternative formats (non-text) including audio, video, images, etc.; dynamic sites where information is searchable. Specific examples are people finder directories (AMA, ABA, etc.); patent databases; legal; medical; multimedia, job search sites, travel sites, etc. Deep web information is frequently proprietary (library databases are an example).
Estimates vary as to the percentage that remains untapped by general search engines. Some say upwards of 80-90% of information is not accessible to those general search engines.
General search engines, at this moment, are unable to enter databases or retrieve their contents because the databases are often dynamically generated lacking fixed URLs or need a user-constructed search to function. Google, for an example, is quite closed about what parts of the web it is able to mine and the algorithms behind those searches. We know that Google can mine (or index) parts of these sites but Google is elusive about the depth of its crawl/search. Their reach is only a partial indexing of sites like .gov (census, loc, etc.) Sites that require registration (NYTImes); fee-based (Lexis-Nexis); interactive; behind firewalls are often inaccessible to Google and the like.
Here are some examples of deep websites.
Deep Websites
The Census Bureau: http://www.census.gov
FBI In the Vault: http://vault.fbi.gov/
GPO Access: http://www.gpo.gov/fdsys/
Bureau of Labor Statistics: http://www.bls.gov/
Bureau of Justice Statistics: http://www.bjs.gov/
Library of Congress: http://www.loc.gov/
PubMed: http://www.ncbi.nlm.nih.gov/pubmed (found on the ZL Online Resources Page)
Gallup Poll News Service: (Lexis Nexis database found on the ZL Online Resources Page) Source Directory Find--[keyword--Gallup Poll News Service > OK to continue. Kw to searchable topic i.e. social media http://www.lexisnexis.com/hottopics/lnacademic/?
Trending Information Sites
StumbleUpon: http://www.stumbleupon.com/
FindLaw: http://www.findlaw.com/
Wolfram Alpha: http://www.wolframalpha.com/
Yippy: http://www.yippy.com/
News Websites
Deep Web Taylor Sites & Sources
Taylor Publications Index: http://www2.taylor.edu/pubindex/
The Echo (1913-Spring 1922 and 1972 – present)*, Taylor Magazine (1963-present), the Gem (1898-1920)*, and the Express (1996-2007) are being indexed and can be searched via the Index to Publications. (Note this index is incomplete.)
Taylor Yearbooks: The Gem; Illium found in Internet Archive https://archive.org/